
You should already have a parser and appropriate expression/tree classes available from your work on the last two assignments. Once you have a tree representing a (valid) expression, you can traverse it in right-to-left, bottom-up order to produce assembly code (this is the "back end" of the compiler). (Note that this traversal order is the same as for your interactive evaluator.)
It may be difficult to complete the compiler for the whole language all at once. I recommend taking a progressive approach, so that you implement only a few language features at a time. Adding fancier features in "layers" will allow you to keep a more-or-less complete working program at various checkpoints along the way, so that you have something to turn in should a deadline arrive.
Examples: "0", "1", "10", "235", "2047".
Examples: "x", "y", "abc", "xyz".
Examples: "x=3", "y=y++", "z=READ+x", "2*(n=READ+1)".
Examples: "x++", "x=y++", "x+++y++", "p~~".
Since multiplication is not supported directly on the PC-231, you'll need to implement this as in-line code, a sub-routine call or in terms of SHIFT instructions.
Examples: "2+3", "2*(3+x)", "10-x*2+y=3".
READ expression returns a value read from the user, dynamically.
Note that this happens at the time the expression is evaluated, so you must
generate code to read in a value from the user (the PC-231 READ expression is
the obvious thing to use, in decimal mode, into a register used to temporarily
hold the value).
Examples: "READ".
WRITE expression writes the value of its sub-expression out,
but has that same value as its value. This is useful for debugging your expressions,
and I usppose for simulating more complex statement-like behavior, but it doesn't
have any effect on the expression itself.
Examples: "WRITE 2", "2+(WRITE x=3)".
produces: 10 (addition is done first, then multiplication).
produces: 22 (multiplication is done first, then subtraction, and finally the addition).
produces: 189
produces: 37 (assuming the first (rightmost) READ yields 15 and the second (leftmost) READ yields 7).
produces: 19 (note that the expression parses as "((x*(x++))+10)-(x=3)"; the value of the rightmost x is 3, the value of the middle x is also 3, and the value of the final x is 4 because of the ++).
produces: 18 (assuming the value read is 5; note that the expression parses out as "((2*(x++))+10)-((x=3+(x=READ)))"; the result then follows from right-to-left evaluation. x is left with the value 4).
(Special thanks to Fletcher for spotting a correction or two above!)
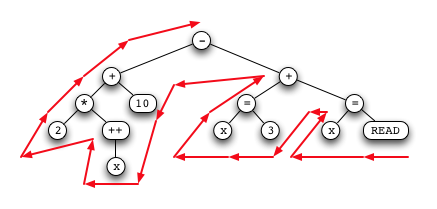
(Note that this tree is not the same as the one from the previous lab: it clearly resulted
from parsing something more like "2*x+++10-((x=3)+x=READ)".)
The issue of register allocation can be simplified consiuderably by storing temporary results or simulating an operand stack in memory, rather than in registers: using RAM will be considerably slower and may use up so many instructions that you won't be able to compile a larger expression. Use whichever strategy you wish, but be aware of the limitations of your own compiler.
In general, there are a number of places where errors might be caught: do your best to catch any errors you think are reasonable (consult with me if you are unsure), but try to concentrate on handling correct expressions properly. You can always add more error checking (or more sophisticated error reports) at a later time. ‚Pé -->
You will also need some general strategies for handling registers and RAM locations. In order to generate code for an integer literal, you will need to put it into some register, and you will need to know which ones are free for this purpose. Assuming that register R3, for example, is free, you might generate code like this for the integer literal 5:
You will also need to know which register the result of a given sub-tree is stored in, so that the node above it can access it properly. For example, if the integer literal 5 from above occurs as a sub-tree of an addition operator node, you will want to generate code such as the following:DATA 5 COPY DR,R3
As mentioned in above, you can use a free register list in order to keep track of register usage. This list can then be modified as you pass from node to node in the tree. In the example above, you would remove R3 from the list as you passed through the node for the integer literal 5, and then add R2 back into the free list after passing through the addition operator node.DATA 5 ; from above COPY DR,R3 ; from above ADD R2,R3 ; assuming other argument was in R2 ; result of the "+" node is in R3 ; and now R2 is free again
It is possible that a straight-forward use of registers will leave you with no free registers at certain points in the process, especially for larger expressions. If this happens, make sure you are using the free list properly, but you need not go the length of "spilling" registers out into RAM locations. In other words, it is OK if your algorithm fails for some large expressions, as long as you are doing your best to free registers as you go. (Note that if you use RAM for temporary values or the operand stack, you won't need to worry so much about register usage.)
Variables can be handled by setting aside a RAM location for them and then loading them into a register and proceeding as above (i.e., noting the register used in the node somehow). For example, an expression such as "x=(x+2)" might compile as follows:
; code for int lit "2" DATA 2 ; int literal 2 COPY DR,R0 ; R0 now in use ; code for var "x" DATA #X ; label for var x storage LOAD R1,DR ; load x using DR indirectly ; code for op "+" ADD R0,R1 ; free up R0, result in R1 ; code for assignment to "x" DATA #X ; set up for store using DR STORE R1,DR ; store x, result in R1 . . . ; etc., etc. HALT ; end of program #X CONST 0 ; placeholder for x #Y CONST 0 ; placeholder for y . . . ; etc., etc.
Handling the multiplication operation will be a bit tougher than the rest: you will need to jump out of the main line of evaluation to a "subroutine" which implements multiplication for you, and then jump back when it is finished. You may use your multiplication routine from a previous lab for this, but note that you will need to do some extra work to make sure that you have left registers for the multiplier to use, a register for the result, and a couple of jump registers for the "call" and "return".
The various other kinds of expressions are much easier to handle. You should probably try generating machine code for some simple expressions by hand until you are comfortable with the techniques before trying to code it up for the compiler. I will add some more detailed hints on code generation strategies for the various expression types, including multiplication, later in the week.
At the root of your tree, you should remember to generate a WRITE instruction which will print out the final value you have computed. Forgetting this step leads to a disappointing anti-climax in which you may have computed the right value, but can't tell, since it never gets printed!