
|
|
The specific expression language you will work with is described below in more detail using a context-free grammar written in extended BNF syntax. The grammar given is for abstract syntax, so it only describes the different kinds of expressions and the type and order of appearance of their constituent sub-expressions. Real expressions will use parentheses to disambiguate structure: we'll see some precedence rules below.
Your major problem in this lab is to decide how to parse the input. Several natural choices come to mind:
<expr> ::= <int-lit> (integer literals)
| <var> (variables)
| READ (input)
| WRITE <expr> (output)
| <var> = <expr> (assignment to variables)
| <var> <p-op> (postfix operators)
| <p-op> <var> (prefix operators)
| <expr> <bin-op> <expr> (infix operators)
| <expr> ? <expr> : <expr> (conditional expression)
| ( <expr> ) (parenthesized expressions)
<int-lit> ::= <digit>+ (non-empty sequences of digits)
<digit> ::= 0 | 1 | ... | 9
<var> ::= <alpha>+ (lowercase only, no digits)
<alpha> ::= a | b | ... | z
<bin-op> ::= + | - | * (arithmetic, but no division)
| < | > | == (relational)
| & | | (logical)
<p-op> ::= ++ | --
Below are a few notes on the syntax (and informal semantics).
READ expression returns a value read from the user, dynamically;
the WRITE expression writes the value of its sub-expression out,
but has that same value as its value. This is useful for debugging, etc.
3*x++" could never be interpreted as
"(3*x)++" anyway).
Multiplication takes precedence over addition and subtraction; the latter two are of
the same precedence. Relational operators are all of the same precedence (but lower than
the arithmetic ones), and logical operators are lower than relational ones.
Operators of the same precedence associate to the left, so that
"2+3-4" is the same as "(2+3)-4".
Assignment has the next highest precedence, so that it is always performed last
of the "operators" (i.e., "x=3+2" is interpreted as "x=(3+2)" rather than
"(x=3)+2"). Of course "x=y++" parses as "(x=(y++))".
The WRITE form has a lower precedence than any
infix operator (even considering assignment one of these),
and the conditional expression has the lowest precedence of all, so that
"x + WRITE x = y++ * 2" is parsed as "(x+(WRITE(x=((y++)*2))))" and
"x==3 ? y++ : WRITE y" is parsed as "(x==3) ? (y++) : (WRITE y)".
2+3*5
produces: (2+(3*5)).
2+3*7-1
produces: ((2+(3*7))-1).
2*x*x + 3*x=7 + 2
produces: (((2*x)*x)+(3*(x=(7+2))))
READ + READ * 2
produces: (READ + (READ * 2)).
x*x+++10-x=3
produces: (((x*(x++))+10)-(x=3)).
Note that error-checking is an important part of the assignment: you should be able to reject any expressions which do not fit the syntax given in this lab write-up. The minimum requirement is to just reject the ill-formed expressions: of course, it's better if you can describe to the user just what has gone wrong, but (as you'll find out), giving good feedback can be quite difficult with syntax errors.
It may be convenient to convert the input string into tokens (or "chunks") before trying to apply a parsing strategy (note: this is a different use of the term "token" than Java uses in "StringTokenizer", although the latter may be helpful). You can either cull out tokens as a separate phase or just handle them dynamically as part of the parsers input routines. See the section Parsing strategy below for details on token handling.
You will probably want to work through several example expressions by hand, using the parsing strategy of your choice, in order to make sure you understand the structures and process involved.
|
|
|
Even if you use one of the other strategies, you may want to read through this section in order to get a feel for some of the parsing issues this grammar presents.
The first stage in parsing, conceptually at least, is to break the input string up into tokens. Our expression language has been designed to make this phase very simple: in most cases, characters in the input can be categorized and handled in a general way (e.g., alphabetic characters and digits can be consumed one after the other and combined to produce a variable or literal). White space can be essentially ignored, since variable names and integer literals can never occur immediately adjacent to another instance of the same token class. The "+" and "-" characters should signal a one-character "look-ahead", since two adjacent occurrences should be taken as a postfix increment (++) or decrement (--) operator.
(There is some possible ambiguity here due to the possibility of binary operators
such as "+" occurring next to prefix and postfix operators such as "++", as in an
example like "x+++y". Let's agree that the tokenizer can "eagerly" grab duplicate
occurrences of a character like "+" and turn them into a single "++" token, so that
the previous example would be seen as "[x] [++] [+] [y]" in terms of tokens. Then the
parser will have no choice but to accept this as "(x++)+y".)
To continue with larger syntactic structures, infix expressions can be parsed from a series of tokens using two stacks, and the basic algorithm can be modified to accommodate postfix operators and assignment as they appear in our language. One stack is used to hold parse trees under construction (we'll call this the argument stack), the other to hold operators (and left parentheses, for matching purposes; we'll call this the operator stack).
As we read in each new token (from left to right), we either push the token (or a related tree) onto one of the stacks, or we reduce the stacks by combining an operator with some arguments. Along the way, it will be helpful to maintain a search state which tells us whether we should see an argument or operator next (the search state is a refinement which helps us to reject certain ill-formed expressions: if you don't see how to use it at first, leave it out until later).
The basic rules for handling individual tokens can be summarized as follows:
Exercise: what is the appropriate way to treat the precedence of the left parenthesis as it sits on the operator stack? Try a short example to see what it should be.
The rules for reduction are a bit simpler: if we see a binary operator on top of the operator stack, we should have two trees on top of the argument stack, both representing expressions. We pop the operator and two trees off, combining them into a single tree node, which is then pushed back on the argument stack. Note that the trees on the argument stack represent the right and left arguments, respectively: this is the opposite of what you might expect. There is a special case when the operator is an assignment: we should then check that the second tree on the argument stack is just a variable leaf node before building and pushing the combined tree.
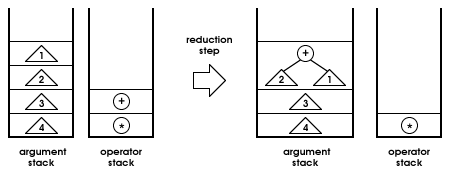
Any other combinations (e.g., no operator on top of the operator stack, or not enough trees on the argument stack, or no variable to go with an assignment operator) should be considered an error.