Programming Project #3: Converting Regular Expressions to Finite Machines
Assigned: Mon 26 Mar 2001
Due: Fri 6 Apr 2001
For this project you will write a program which reads in a regular expression as
input, converts it into a finite automaton (these correspond to the "configuration
phase") and then repeatedly reads input strings and reports on whether or not they
are members of the language associated with the regular expression.
Perhaps the hardest part of the problem is the reading and parsing of the regular
expression input itself: although regular expressions describe regular languages
(of course!), the language of regular expressions is itself a
context-free language. More specifically, we'll use the following context-free
grammar to formally define the concrete syntax of regular expressions we'll
use for the assignment:
By way of example, the short regular expression shown in Example 1.30 on page 68 of
the text would be written as:
In order to parse a regular expression, you will likely need a stack or two. You are
welcome to develop your own algorithm for the parsing (you could even base it on the
general techniques described in the book for arbitrary CFG's), but there is a
standard method for a similar language of arithmetic described in
this lab from the programming languages class.
Our language of regular expressions is actually quite a bit simpler, in that
all "tokens" can be represented by single characters, and the default rules for
parenthesization make much of the precedence processing unnecessary. Nevertheless,
if you are having trouble coming up with an algorithm on your own, the ideas
described for the more complex numeric expressions should be helpful.
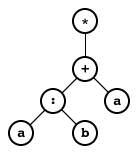
By way of example, the regular expression from the example above would correspond to
the following tree:
In any case, the hardest part of the lab will be the parsing of the expression into
an internal tree structure: from there, you should easily be able to convert the
regular expression into a DFA (or NFA, or one after the other) using the techniques
described in the textbook; see Sipser pages 66-69 (you may even find that you can
output the automaton as you parse, without generating a separate tree structure).
Once converted into a DFA or NFA,
you should be able to use code from prior labs to check for membership in the
corresponding regular language.
Remember that, for your demo, it should be possible for you to quickly enter in
a regular expression during the configuration phase, then repeatedly
enter and check strings against that expression (i.e., for membership in the
corresponding language).
As usual, you may use any language or platform you wish for your
implementation; the only restriction is that you be able to demonstrate your
program for the instructor, either in lab during regularly scheduled hours, or
by advance appointment in some other easily accessible place (e.g., the student
research lab, WITS labs, instructor's office, etc.).
![]()
That is to say, a regular expression consists of:
R -> S | # | @ | ( R : R ) | ( R + R ) | R *
S -> a | b | ... | z | 0 | 1 | ... | 9
Note that we require parentheses around expressions formed with binary
infix operators: if we further specify that the postfix Kleene star binds tightest,
we have a relatively easy to parse and unambiguous language. You may optionally allow
parentheses to be elided according to the usual rules as given in the text (i.e.,
with concatenation given higher precedence than union). Note that the binary operators
are associative and therefore, if you choose to allow elision of parentheses,
you needn't worry about the order in which you associate
them (which way is easiest will probably depend on your parsing technique).
((a:b)+a)*
![]()