RE type, we have a
Show class instance which tells how REs should be printed
out (here they are fully parenthesized and written as ASCII: not very
pretty, but readable in your terminal and at least overt about structure).
(There is no show instance given for DFAs due to their transition
function: in general, Haskell will not print out functions, although we
could get it to work for these simple ones. In any case, the DFAs are
very easy to read in the input format used in the file.) The two helper
functions pop and par are used to format
binary operations (etc.) in an infix style with parentheses.
Try printing out some of the sample REs by just entering their names (e.g.,
axb, baa, or swd). Can
you read them and understand their structure?
match relation: This relation (i.e., boolean-
valued function of two arguments) takes an RE and a string
and tells whether the string matches or not. Thinking of it as a function
from REs to string-predicates, we can think of it as giving
a predicate semantics to each RE. For most of the cases this
is pretty straightforward, but the last two use a combination of the
(pre-defined) any function (can you figure out what it does,
say using its type and perhaps Hoogle?) and a helper function part
that partitions a string into two pieces in all possible ways. (Try the
part function out yourself on a couple of sample strings.)
REs and back-ticked operators: Haskell has a
couple of useful features for infix operators: “symbolic”
operator names are infix by default, but can be referenced as prefix by
enclosing them in parentheses. On the other hand, when convenient,
“named” operators (like the constructor Dot) can
be referenced as infix by surrounding their names in “back ticks”,
found in the upper-left corner of the keyboard (note: not single quote marks!).
Here I have used this feature to make the examples read a bit easier; also note
the used of defined variables to make things like the literals 'a'
and 'b' easier to digest. Finally, the definition of the
plus operator is an example of how we can use the features of the
meta-language (in this case Haskell) to get a bit of “syntactic sugar”.
But if you print out an example that uses the sugar, you’ll see that it
is only there in the definition, not in the actual value of the example.
match function by
testing it on some of the REs given here: the names are a bit
whimsical, but see if you can tell what they do by finding some sample strings
that you can predict their behavior on. (Once we get to the bottom of the
module we will see some utilities that help do some “wholesale”
testing.)
DFAs: The next algebraic data type is for DFAs,
and again it follows our lecture definition almost exactly, differing only in
that it uses a “curried” constructor (of the same name as the type)
taking several arguments (rather than a 5-tuple), and in that some of the
components are represented using lists rather than sets. Note the inclusion of
type constraints that specify that states and symbols must support equality
(the “(Eq q, Eq s) =>” part). We might also have
defined our automata using separate types for the states and symbols, but this would
make some of the constructions more difficult: in return, we have to pay a small
price in checking these machines for validity, since they might otherwise not be
well defined (this is the check function; can you see what it does?).
One other thing to note in the
data type definition: the name of the
type being defined is "DFA" … but the name of the
constructor for values of this type is also "DFA".
This is one of a few conventions people use when a data type has only one
constructor: another is touse something like "MkDFA (“make
a DFA”). In either case, you can think of it like calling
"new ConstructorName();" in Java.
[ … | … ]"
notation is what is called a “ZF comprehension” in Haskell.
It is intended to look like the similar feature in standard set theory
notation; it’s meaning is also similar, but it defines a list of
results (of a certain shape) based on various list generators and
guards. Try these examples in a terminal to see the idea:
[ x^2 | x<-[1..10] ]: “the list of x squared such that x comes from one through ten”.[ k*3+1 | k<-[1..10], even k ]: “the list of k times three plus one, such that k comes from one through ten and k is even”.[ (x,y) | x<-"abc", y<-[1..4] ]: “the list of pairs x, y such that x comes from a-b-c and y comes from one through four”. (Note especially the ordering here!)
If you need some help understanding this notation, which is also used in a few places below in the file, see this graphical explanation … or just ask for help!
foldl function: In lecture and lab we have seen the
foldr function, which follows the natural structure or
“grain” of a list, replacing its constructors with the parameters
of the fold. The Haskell Prelude features several variations
on this theme, including the foldl function used here: the
difference is that foldl accumulates results from left to right
rather than from right to left as foldr does … and
that’s just what we need to work the transition function across a
string, starting with the initial state, as the acc or
“acceptance” function does. (And once we have the end state,
we merely have to check if it was among the list of final states included
in the definition of the DFA: that’s what elem does.)
@” pattern: In the definition of the
acceptance function acc, there is a use of a pattern with an
@-sign prefix: this feature, read “as”
allows one to name the value which matched a whole pattern, as well as
naming the parts of the value that matched the pattern (with embedded
variable names, in the usual way). It is used here just to make it easier
to check the machine as a whole for validity: otherwise, we would have to
laboriously re-construct the whole machine from its parts on the right-hand
side of the clause: just m is much shorter! (And also saves a
bit of time and space versus an explicit re-construction.)
DFA
to see if a string is in its language (using the acc function),
we can also manipulate DFAs as “objects” in and
of themselves. That is to say, we can for example build new ones from old,
as in the two constructions given here, namely the neg
function, which returns the opposite result by simply complementing the
final state set (relative to the whole), using Haskell’s set
difference function (\\), or by building a machine which
will compute the “simultaneous product” of two machines,
relative to a specified boolean operator, using the prod
function. The latter is the same idea we saw in class, but now fully realized
as a function on Haskell data structures; the former could of course be
simulated by simply negating the result of a run using acc,
but it is nice to see that we can also do it “internally”
via a machine construction.
Note that the
prod construction would be ill-defined if the
alphabets of the machines did not match; also note how the ZF comprehensions
make for a tidy way to describe the (roughly speaking) cartesian product
of lists, and the set of all pairs of final states that satisfy the
combination specified by the boolean operator parameter.
DFAs: Next are included a couple of sample
DFA machine definitions, one (called baam) which
corresponds to the baa “sheep” RE,
and one (called bchm) which corresponds to the bch
“Beach Boy” RE (the latter is named after the
starting lyrics to the popular surf song
Barbara Ann
by the Beach Boys).
Note how closely the format of these definitions follows the tabular style we used on the board in lecture:
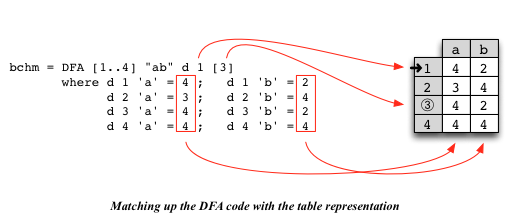
DFA definitions (see below!).
- The
cutfunction allows one to apply a predicate to a list of values and get a pair of lists in return, where the first half of the pair contains a list of all values for which the predicate succeeded, and the second half a list of those that failed. (Can you see how to use this to test a regular expression or a DFA on a list of possible inputs?) - The
winfunction just returns the “good” or first half of a cut—this is especially helpful when the list of inputs is large, but the list of successful ones is small. - Finally, the
lftandrgtfunctions just “inject” a function so that it operates on one or the other half of a pair. (These are used at a couple of points above, including in the definition ofcut.)
cut or win from
immediately above, as well as the acc
functions. gen generates all the strings over {a,b} of a
specified length (in lexicographic order, even!). abs
(pronounced “ay-bees”) yields all the strings up to
a given length, inclusively, ordered by length and then lexicographically.
And get takes the first k strings from the same list, not
by length, but just by raw number of strings, since that is sometimes
more convenient.