
 (one
output node)
(one
output node)
where
ti = desired target value associated with the i-th example
yi = output of network when the i-th input pattern is presented to network
![]()

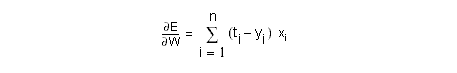
If there are mor ethan 2 classes we could still use the same network but instead of having a binary target, we can let the target take on discrete values. For example of there ar 5 classes, we could have t=1,2,3,4,5 or t= -2,-1,0,1,2. It turns out, however, that the network has a much easier time if we have one output for class. We can think of each output node as trying to solve a binary problem (it is either in the given class or it isn't).

