Pattern Classification And Single Layer Networks: Chapter 2
Intro
We have just seen how a network can be trained to perform linear regression. That is, given a set of inputs (x) and output/target values (y), the network finds the best linear mapping from x to y.
Given an x value that we have not seen, our trained network can predict what the most
likely y value will be. The ability to (correctly) predict the output for an input the network has not seen is
called generalization.
This style of learning is referred to as supervised learning (or learning with
a teacher) because we are given the target values. Later we will see examples of unsupervised learning
which is used for finding patterns in the data rather than modeling input/output mappings.
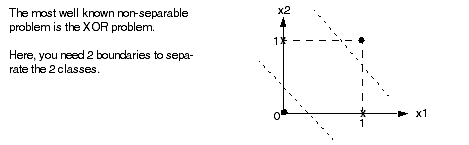
We now step away from linear regression for a moment and look at another type of supervised learning problem called pattern classification. We start by considering only single layer networks.
Pattern classification
A classic example of pattern classifiction is letter recognition. We are given, for example, a set of pixel values associated with an image of a letter. We want the computer to determine what letter it is. The pixel values are refered to as the inputs or the decision variables, and the letter categories are referred to as classes.
Now, a given letter such as "A" can look quite different depending on the type of font that is used or, in the case of handwritten letters, different people's handwriting. Thus, there will be a range of values for the decision variables that map to the same class. That is, if we plot the values of the decision variables, different regions will correspond to different classes.
Example 1:
Two Classes (class 0 and class 1), Two Inputs (x1 and x2).
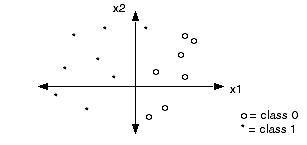
See also: Neural Java 2 Class Problem
Example 2:
Another example (see data description, data,
Maple plots):
class = types of iris
decision variables = sepal and petal sizes
Example 3:
example of zipcode digits in Maple
Single layer Networks for Pattern Classification
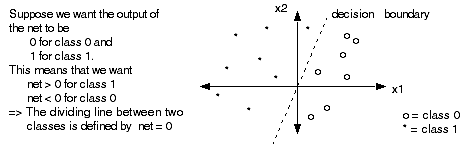
We can apply a similar approach as in linear regression where the targets are now the classes. Note that the outputs are no longer continuous but rather take on discrete values.
Two Classes:
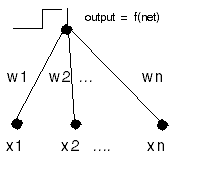
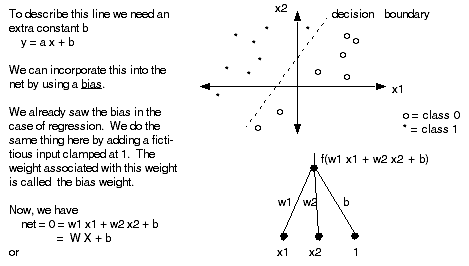
What does the network look like? If there are just 2 classes we only need 1 output node. The target is 1 if the example is in, say, class 1, and the target is 0 (or -1) if the target is in class 0. It seems reasonable that we use a binary step function to guarantee an appropriate output value.