See Me Rolling
Jed Rembold
March 4, 2026
Announcements
- Homework 7 is out and due on Monday!
- Everything you’ll need you have after today
- I am continuing my quest to get caught up on grading
- Adding this new content this week slowed it down, but I think the new content is worth it
Recap
- A transit happens when a planet passed between its parent start and our line-of-sight
- The dip in brightness gives us information about the size of the planet \[\text{Fraction of light lost} = \frac{R_{planet}^2}{R_{star}^2}\]
- The shape of transits means that we see many harmonics when using FFT or Lomb-Scargle methods, which come from the Fourier series components
- A better method with transits is to use a Box Least Squares method
Discussing Today
- Prepping data for BLS
- Flattening with rolling medians
- Zeroing
- Grid Search options
- Using BLS libraries
- Extracting physical data
Prepping Data
Flattening
- BLS in sensitive to changes in the star brightness that are not due to a transit
- So we need to level everything else out, without affecting the transit drop
- Could fit a high-order polynomial, but those are usually very impacted by possibly outliers
- A better, and arguably simpler approach, is to subtract a rolling median
Rolling
- A “rolling” statistic looks at a surrounding window for
each point in a data set, and computes some descriptive statistic over
that window
- Rolling means/averages or rolling medians are probably the most common
- Main choice is in the size and placement of the window
- Bigger windows have bigger effects on the resulting data (more smoothing)
- Windows can be centered on a point, come before, or come after
- Algorithms can vary, but the basic algorithm is just looking at
position of data within the series, so it does not
account for data spacing.
- Data ordering matters!
Sorting
You should always ensure your data is sorted before computing a rolling statistic on it
In Python, with pandas:
df = df.sort_values(colname)In R, with Tidyverse:
df <- arrange(df, colname)
Rolling in Python: With Pandas
Computing the rolling statistic is then straightforward:
df['rolling'] = df.col.rolling(wsize).statistic()where
colis whatever column you are computing the average over, andwsizeis the size of the window you wantwsizeis just a number of data points
statisticis usually eithermean()ormedian()Default window placement is right-aligned, so window comes before data
Rolling in R: With Zoo
Easiest to use
rollmean(orrollmedian) from thezoolibrarylibrary(zoo) df <- df %>% mutate( rolling = rollmean(colname, k=wsize) )wsizeneeds to be odd forrollmedianDefault window placement is centered
Literal Edge Cases
- When you compute a rolling statistic, points near the edge of the
dataset will not have a full window, leading no
NaNs orNAs - The BLS algorithm does NOT handle these well
- In Python, can set
min_periods=1to have the window “grow” out on edges - In R, can set
fill='extend'to have it pad outNAwith the closest value - Either is fine so long as your transit isn’t super near the edge of your data
Applied to Transits
- With transits your goal is to choose a window that is definitely bigger than a possible transit duration (which is usually less than a couple hours)
- If your window gets too big, it will start doing a bad job flattening the data (wiggles or slopes will remain)
- To flatten, you want to subtract the rolling median from the original data
- This will mostly zero it out as well, but it is then never a bad idea to subtract the entire median from the data to ensure it is fully “zeroed”
Practice Activity
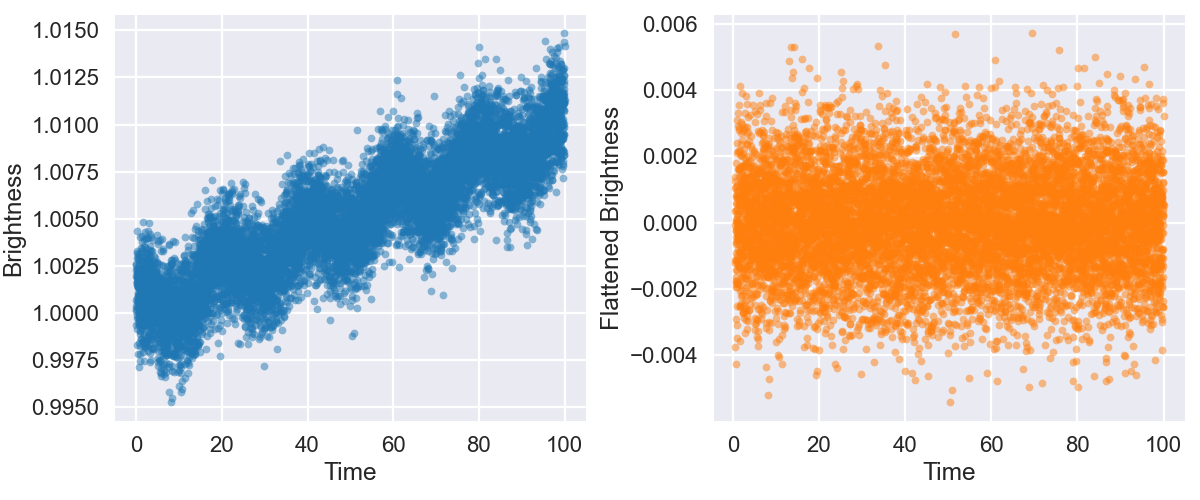
- The file here depicts a brightness curve over 100 days
- There is evidence both of a general slope to the data and some oscillations unrelated to anything of interest
- Flatten the signal out and zero-center it, as if you were preparing it for BLS
Running BLS
Setting up the Grid Search
- We have several parameters to vary in our grid search
- What periods to test
- Really, we want to do this in frequency space for nice linear steps
- A good rule of thumb is to take steps no larger than \[ \Delta f = \frac{0.01}{t_{span}} \]
- Ranging from periods of about 0.5 days to 20 days
- What durations to test (size of box)
- This is a fraction of the normalized phase, usually between 0.01 to 0.1 or 0.15
- The number of bins we want to break the phase space up into
- Generally numbers of bins between 200 and 1000 work well
Using the Libraries
- I’ve packaged most of the BLS machinery into a
bls_searchfunction for you - Exact same parameters in Python and R
- The array of observation times
- The array of observation brightnesses
- The array of all periods you want to test (just do 1 / frequencies)
- The number of bins you want to divide the phase-space into
- The smallest duration you want to test
- The largest duration you want to test
- Each will return a dataframe of the best found values at each tested period
Further Usage Comments
- In Python, you can just import the function in your code
- In R, you need to
source()the appropriate file- You actually have 2 possibilities:
bls.rwill for sure work, but it will be much slower (about 7x in my testing)- Might take 3-10 minutes to run
bls_fast.rcompiles some C++ code to run in R that makes it the same speed as the Python version- Requires Rtools in Windows
- Requires XCode in macOS:
xcode-select --installin terminal
- You actually have 2 possibilities:
Analyzing Results
Periodogram
- The output of
bls_searchincludes both period and power columns, so creating a periodogram is easy - You are still likely to see multiple peaks here
- Recall how with phase folding things still seemed to line up “somewhat” when we were at integer multiples of the true period?
- Same advice applies at looking for the largest peak that is near the lowest frequencies
- Can determine with a peak_finder or, if the largest, just filter it out of the table
Peak Depth
- Recall that the BLS algorithm computes \(s\) and \(r\) values as it slides along each phase-folded signal. These actually have all the depth information hidden within them
- For a given peak period, you can compute the depth of the signal with: \[ \text{Depth} = \frac{|s|}{r} + \frac{|s|}{N-r} \] where \(N\) was the total weight (number of observations)
- You can and should probably check this against a smoothed, phase-folded version of the signal
Duration and Timing
- BLS also scores the best fitting duration and location
- Both are given in terms of the bins, so need to take into account the number of total bins that you used \[ \text{Duration} = \frac{\text{duration in bins}}{N_{bins}} \cdot \text{Period} \] \[ \text{Starting Phase} = \frac{\text{start bin}}{N_{bins}} \]
- These can also be compared/checked against a smoothed, phase-folded version of the signal