---
title: "The Dark Forest"
author: Jed Rembold
date: April 1, 2025
slideNumber: true
theme: tokyo-night-light
highlightjs-theme: tokyo-night-light
width: 1920
height: 1080
transition: slide
---
## Announcements
- HW4 is due on Thursday evening!
- Quiz 2 on Exoplanets and Galaxies a week from Thursday
- Review and study materials will go out on Thursday
- HW2 feedback went out!
- Do you want to use it to make any changes to HW3? They need to be done and submitted by Friday at noon. My goal is to try to see if I can get through HW3 feedback this weekend
- Will start our next unit on Thursday
## Recap
- For certain data, alternative models are necessary to capture relationships within the data
- Decision Trees are one alternative method of creating a classifier model
- Comprised of a conditional tree of yes/no questions
- Each question attempts to minimize the resulting overall "impurity" of the classifications
- Utilizing a full decision tree will often _overfit_ the data, and thus various parameters can be chosen to "prune" the tree
- Decision trees are unstable in that the resulting tree can heavily depend on the randomized initial training data
## Discussing Today
- Combining Models
- When and why might an ensemble of models give better results?
- How can we easily generate new "models"?
- Introducing and understanding random forest models
# Strength in Numbers
## Why Ensembles?
- Ensembles leverage the idea that many efforts trying to get the right answer will be off in a **random** way
- This is in fact what the Galaxy Zoo project does!
- Most volunteers are not experts, and will make mistakes from time to time
- But the mistakes will be random, and thus averaging them will get close to the correct answer
- You can actually do this with any machine learning model
## Voting Classifiers
- You can construct your own arbitrary ensembles
- In Python:
```python
combo = VotingClassifier(
[
('logreg',log_mod), # first model
('dec_tree',tree) # second model
],
voting='soft')
combo.fit(training_df[['x','y']])
```
- I haven't yet found an equivalent in R, but I'd imagine it is out there
## Gerrymandering (Voting Boundaries)
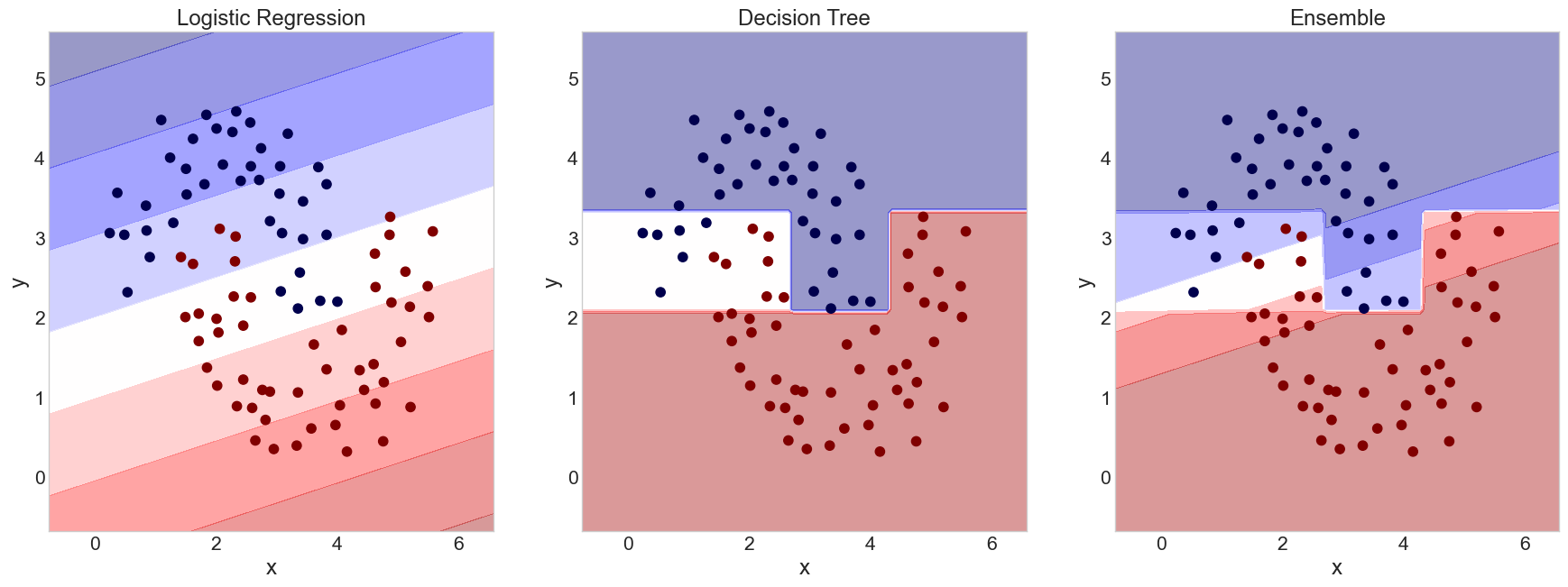{width=100%}
# Generating Chaos
## Creating Model Variations
::::::{.cols style='align-items: center'}
::::col
- Changing the `random_state` won't always generate a very different model
- And in some cases, like logistic regression, there is no random element
- A better way is using _bagging_ (Bootstrap Aggregation)
- In SkLearn as `BaggingClassifier`
- In R from `baguette` library
::::
::::col
::::
::::::
## Bias and Variance
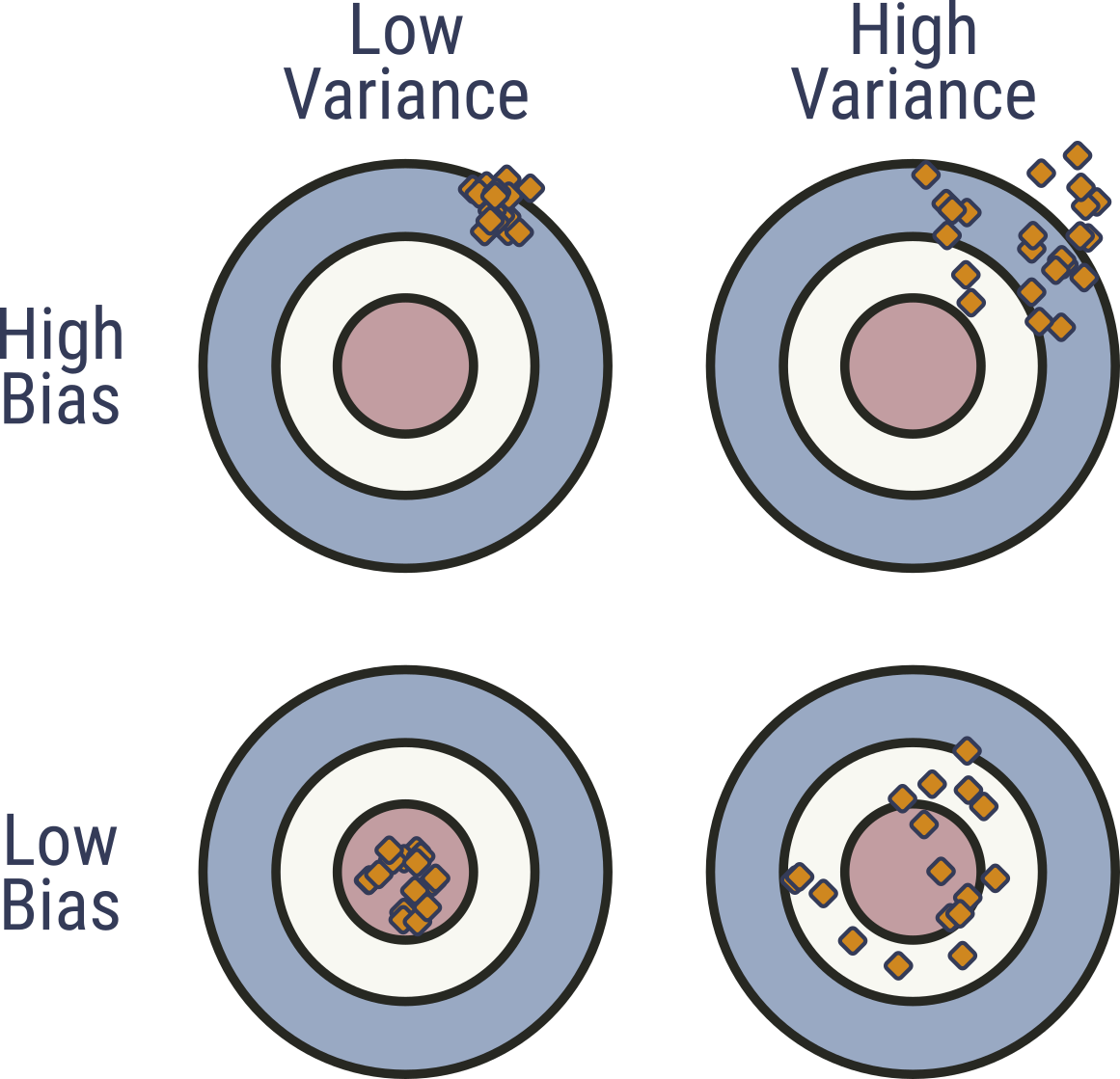{width=50%}
## Applications to Ensembles
- The ability of an ensemble of classifiers to generalize depends on:
- The strength of the individual classifiers (how well does each individual model do at predicting a class?)
- The inverse correlation of the models
- 100 of essentially the same model isn't going to gain you anything in the averaging
- The more distinct the models are in their own unique errors, the better the ensemble will operate as a whole
- Often worth making an individual model worse if it uncorrelates the ensemble models
# Entering the Forest
## Building a Forest
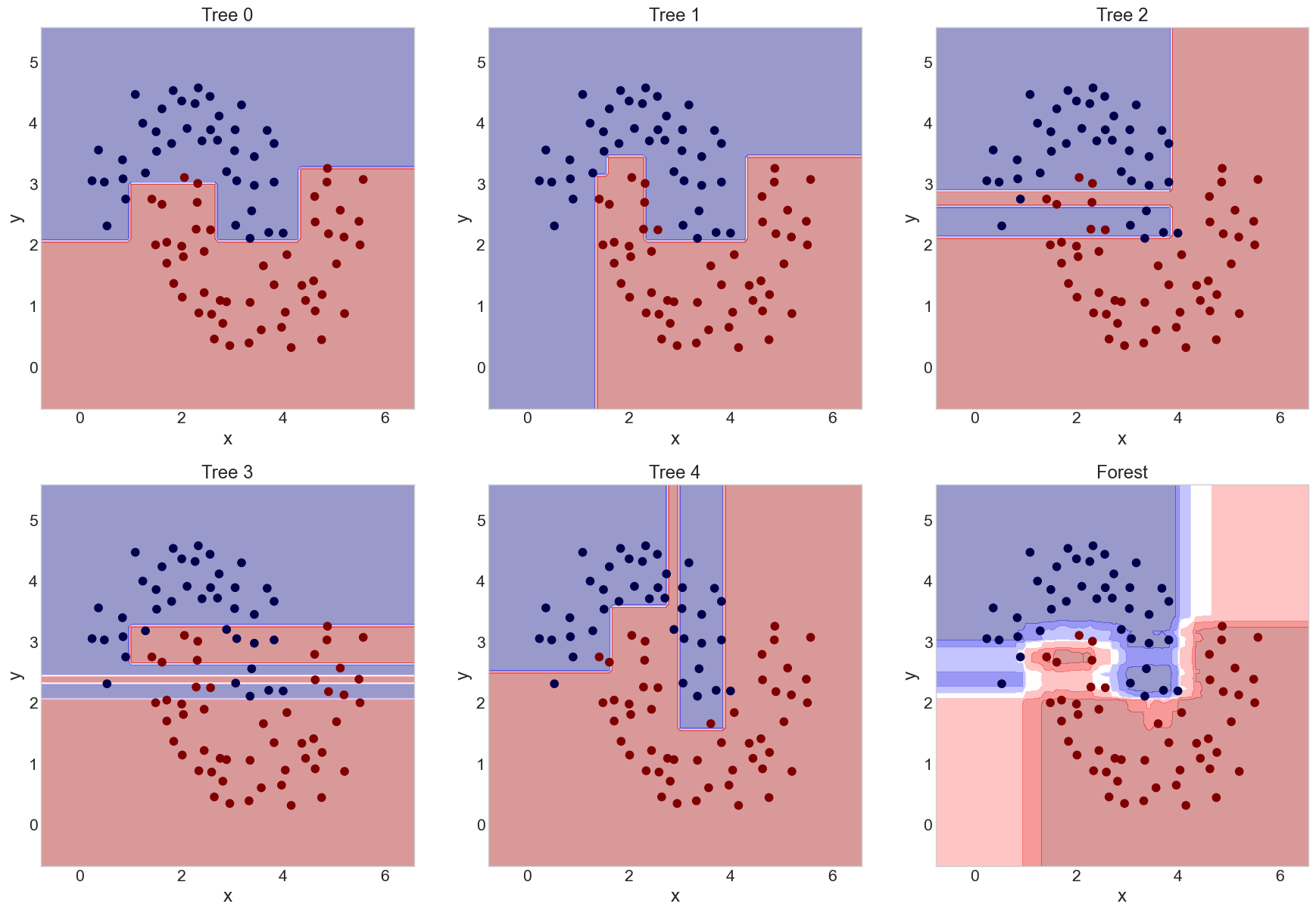{width=70%}
## Randomizing Trees
::::::{.cols style='align-items: start'}
::::col
- Random forests are created by randomizing each tree in two ways:
- Bagging the training data for each tree
- For each split, picking a random subset of features to use
- More trees are always better, but will slow training
::::
::::col
::::
::::::
## Creating a Random Forest
- In Python, random forest models come from the Scikit-learn `ensemble` module
```python
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier()
```
- In R, they are one of Parsnips available models
```r
forest <- rand_forest(mode="classification")
```
- Fitting, computing confusion matrices, visualizing classification boundaries, etc. proceed exactly as they have for other models
# Trimming the Forest
## Tuning Forests (Python)
- How many trees in the forest?
- `n_estimators` (default=100)
- Main tuning parameter: `max_features`
- Determines how many features to keep at each split
- For classification, using about $\sqrt{\text{n_features}}$ is best, and this is the default
- Tree pre-pruning can still help!
- If nothing else with model size and training time
- Still `max_depth`, `max_leaf_nodes`, etc.
## Tuning Forests (R)
- How many trees in the forest?
- `trees` (default=100)
- Main tuning parameter: `mtry`
- Determines how many features to keep at each split
- Default is the same $\sqrt{\text{n_features}}$
- Tree pre-pruning can still help!
- `min_n` is the minimum number of points still in a node to be split further
## Warming Up
::::::cols
::::col
- More trees is always better, but at a cost to time
- How many trees get you the most "bang for your (time) buck"?
- Sklearn's `warm_start` option lets you resume from last training point
::::
::::col
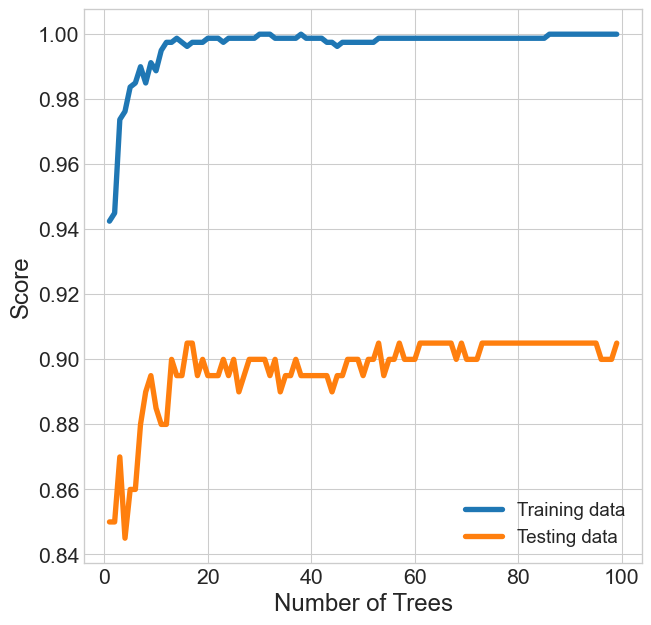{width=100%}
::::
::::::
## Activity
- Taking the same dataset from before ([here!](../demos/basic_labeling.csv)) build a classifier using a random forest
- For several sizes of forest and pre-pruning parameters, create a forest and then compare its confusion matrix to the others.
- If you have a time, see if you can determine the least number of trees you need while still maximizing your model's effectiveness.
# Working Time!
## HW4 Working Time!
- I've set aside the rest of class for you to touch base/work with your partner(s) on HW4
- Ensure you are on track to finish by the end of Thursday!
- What questions do you have? Discuss them with your partner, and then potentially myself