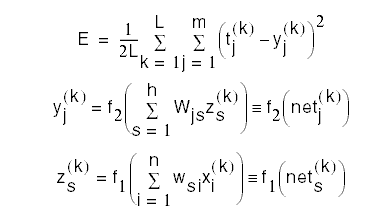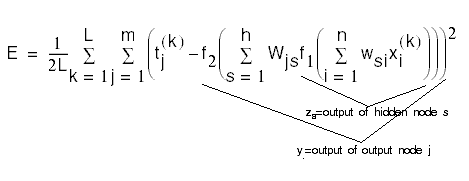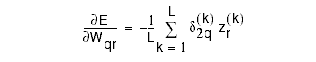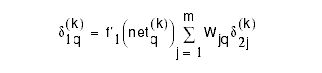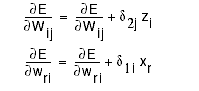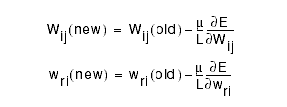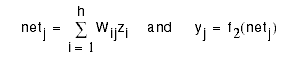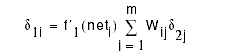Multilayer Networks and Backpropagation
Introduction
Much early research in networks was abandoned because of the severe
limitations of single layer linear networks. Multilayer networks were not "discovered" until much later
but even then there were no good training algorithms. It was not until the `80s that backpropagation became widely
known.
People in the field joke about this because backprop is really just applying the chain rule to compute the gradient
of the cost function. How many years should it take to rediscover the chain rule?? Of course, it isn't really this
simple. Backprop also refers to the very efficient method that was discovered for computing the gradient.
Note: Multilayer nets are much harder to train than single
layer networks. That is, convergence is much slower and speed-up techniques are more complicated.
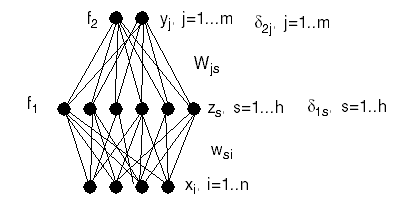
Method of Training: Backpropagation
Define a cost function (e.g. mean square error)
where the activation y at the output layer is given by
- z is the activation at the hidden nodes
- f2 is the activation function at the output nodes
- f1 is the activation function at the hidden nodes.
Written out more explicitly, the cost function is
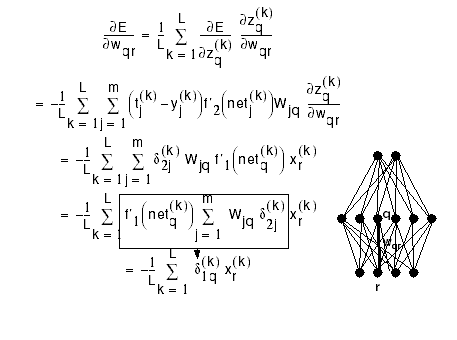
Computing the gradient: for the hidden-to-output weights:
the gradient: for the input-to-hidden weights:
Summary of Gradients
hidden-to-output weights:
Implementing Backprob
Create variables for :
- the weights W and w,
- the net input to each hidden and output node, neti
- the activation of each hidden and output node, yi = f(neti)
- the "error" at each node, ´i
For each input pattern k:
Step 1: Foward Propagation
Compute neti and yi for each hidden node, i=1,..., h:
Compute netj and yj for each output node, j=1,...,m:
Step 2: Backward Propagation
Compute ´2's for each output node, j=1,...,m:
Compute ´1's for each hidden node, i=1,...,h
Step 3: Accumulate gradients over the input patterns (batch)
Step 4: After doing steps 1 to 3 for all patterns, we can now update
the weights:
Networks with more than 2 layers
The above learning procedure (backpropagation) can easily be extended to networks with any number
of layers.
[Top]  [Next: Noise] [Back to the first page]
[Next: Noise] [Back to the first page]